Nội dung bài viết
Video học lập trình mỗi ngày
Nếu bạn đã từng copy, paster từ một trang web nào xuống dữ liệu của mình thì công việc đó chính là "Web Scraping" nhưng chỉ khác là bạn đang làm một cách thủ công mà thôi. Trong bài hướng dẫn học web scraping sử dụng nodejs và javascript này, chúng tôi trình bày 4 cách giúp các bạn có thể lấy được bất kỳ dữ liệu nào của web về database của mình. Đặc biệt, dành cho các bạn kinh doanh thì việc lấy data trên yellowpage (những trang vàng) là một dữ liệu ngon đấy.
Bài viết này dành cho những lập trình viên đã có một chút kinh nghiệm về javascript và nodejs, đối với những bạn chưa có kinh nghiệm thì bài học web scraping cũng sẽ có ích cho các bạn về kiến thức. Nhưng đầu tiên chúng ta sẽ đi tìm hiểu định nghĩa về web scraping.
Web Scraping là gì?
Web Scraping là trích xuất dữ liệu từ một bất kỳ website hay còn gọi là "cào" dữ liệu trên một trang web. Không giống như quá trình trích xuất dữ liệu thủ công, Web Scraping sử dụng tự động hóa thông minh để lấy hàng trăm, hàng triệu hoặc thậm chí hàng tỷ dữ liệu trên internet. Học web scraping cũng không khó, nhất là những lập trình viên sử dụng javascript và nodejs.
Học web scraping
Quy trình làm việc web scraping rất đơn giản, nó không phức tạp. Nhưng đòi hỏi bạn phải tỉ mỉ, cẩn thận mà thôi và hiểu một chút về DOM nữa. Trước tiên chúng ta phải lấy hết data một trang web bao gồm html. Sau đó chúng ta sẽ đọc từng node trên DOM mà chúng ta muốn lấy. Đó là quy trình, không khó đâu. Sau đây là 4 cách học web scraping như thế nào.
Cheerio - web scraping
Ở bài này tôi get dữ liệu từ trang web yellowpages.vnn.vn Các bạn chú ý hình ảnh phía dưới, ở đó là nơi chúng ta sẽ lây dữ liệu của những công ty trên trang đó về.
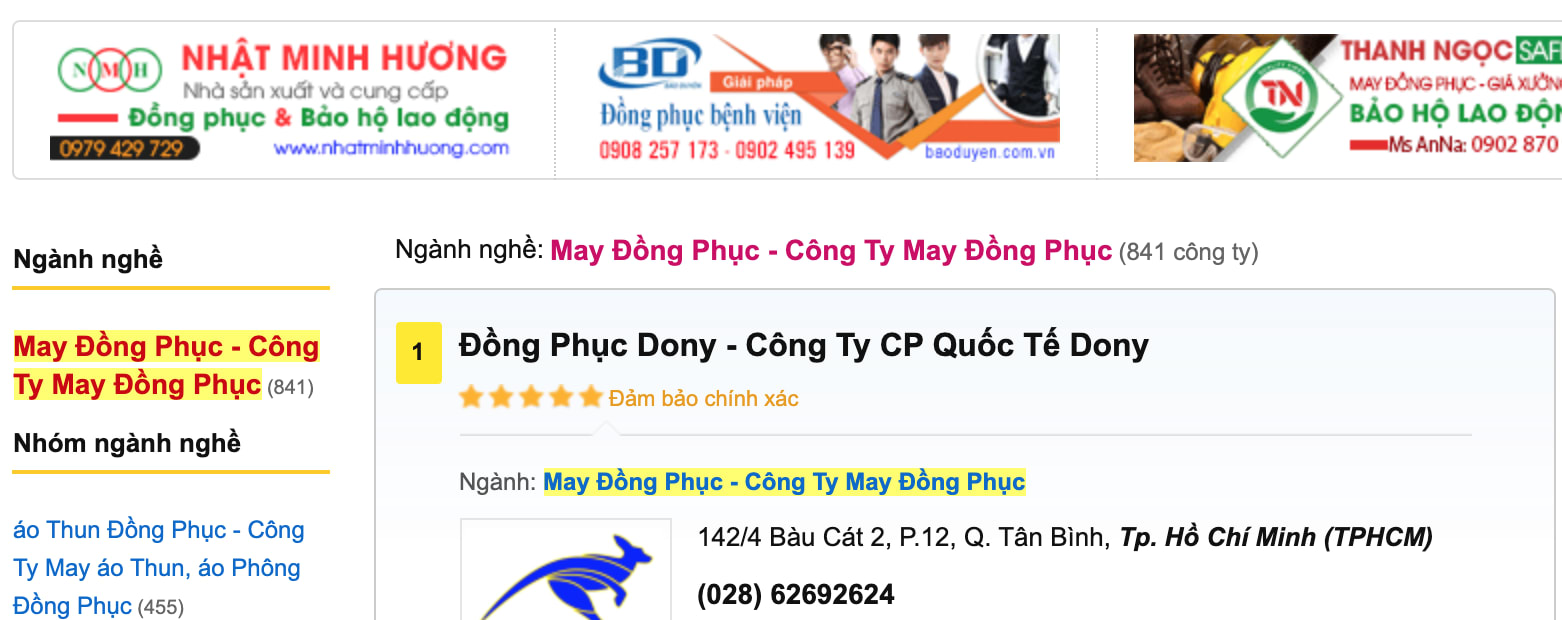
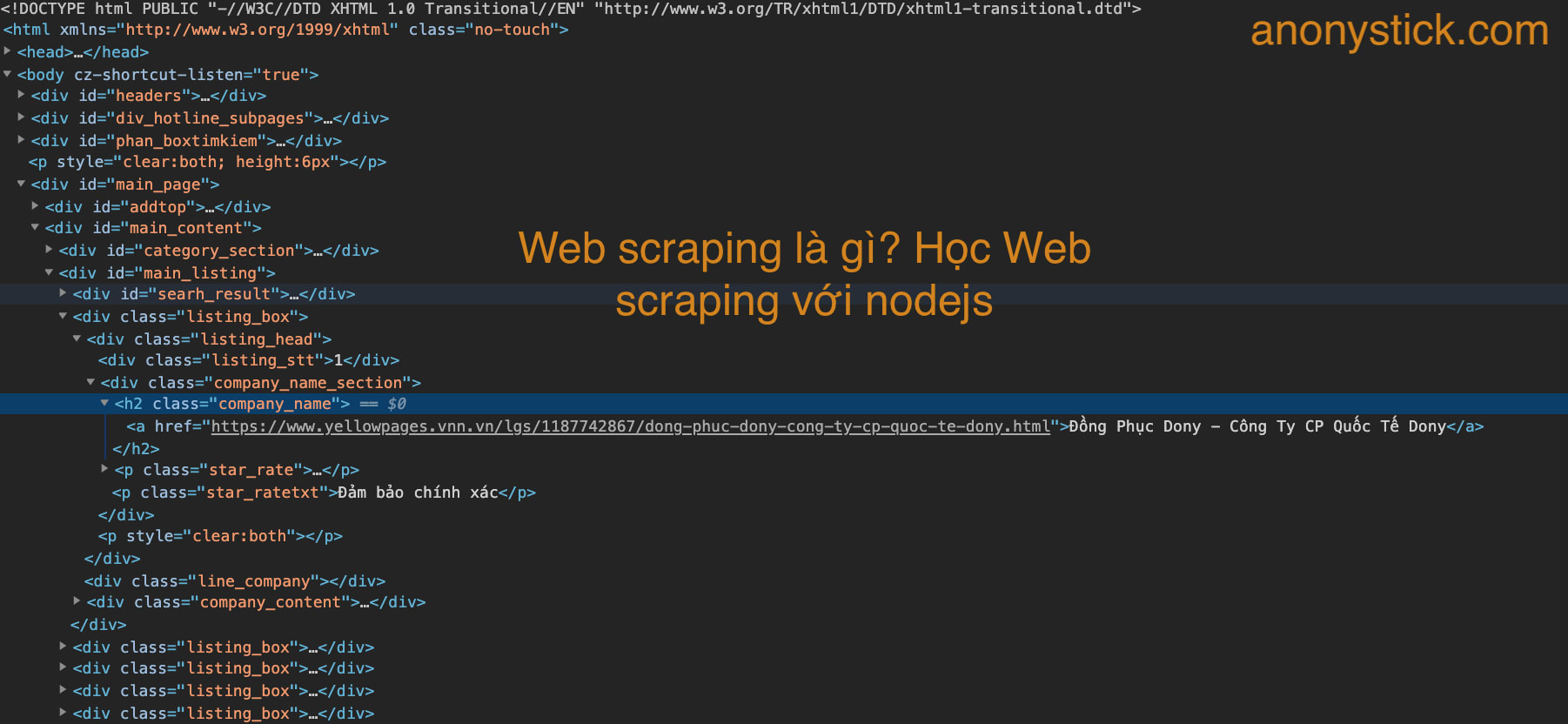
Các bạn mở "view page source" bạn sẽ nhìn thấy "Đồng Phục Dony - Công Ty CP Quốc Tế Dony" nằm trong thẻ a, và thẻ h2 có class="company_name" chính vì vậy ta sẽ lấy dữ liệu dựa vào những chi tiết đó.
Xem hình ảnh cho rõ
# npm i axios cheerio --save
axios là gì thì bạn có thể đọc qua bài viết này, để hiểu sâu hơn về axios. Giờ đây hãy xem với Cheerio chúng ta sẽ tim được những gì.
//web-scraping.js
const axios = require('axios');
const cheerio = require('cheerio');
const getPostTitles = async () => {
try {
const { data } = await axios.get(
'https://www.yellowpages.vnn.vn/cls/268180/may-dong-phuc.html'
);
const $ = cheerio.load(data);
const postTitles = [];
$('div > h2.company_name > a').each((_idx, el) => {
const postTitle = $(el).text()
postTitles.push(postTitle)
});
return postTitles;
} catch (error) {
throw error;
}
};
getPostTitles()
.then((postTitles) => console.log(postTitles));Run file sử dụng nodejs: node web-scraping.js.
//Output: [ 'Đồng Phục Dony - Công Ty CP Quốc Tế Dony', 'Đồng Phục Posido - Công Ty Cổ Phần Posido', 'Chi Nhánh Phía Bắc Tổng Công Ty May Nhà Bè - Công Ty Cổ Phần', 'Công ty TNHH May Đồng Phục Anh Tú', 'Công Ty TNHH Quốc Tế UNI-PRO Việt Nam', 'Đồng Phục Phú Gia Khang - Công Ty TNHH Thương Mại Và Dịch Vụ Phú Gia Khang', 'Đồng Phục Huỳnh Gia Minh - Chi Nhánh Công Ty TNHH Huỳnh Gia Minh', 'Đồng Phục Hải Nguyễn - Công Ty TNHH Thời Trang Hải Nguyễn Vina', 'Đồng Phục Green Nguyễn - Công Ty May Mặc Green Nguyễn', 'May Mặc Thái Tuấn - Công Ty TNHH Xuất Nhập Khẩu Và Thương Mại Thái Tuấn', 'May Đồng Phục Nhật Thịnh - Công Ty TNHH Sản Xuất & Thương Mại Nhật Thịnh', 'May Mặc Diệu Khang - Công Ty TNHH Sản Xuất Thương Mại Diệu Khang', 'Đồng Phục Minh Thành - Công Ty TNHH May Đồng Phục Minh Thành', 'Đồng Phục Thiên Hương Phát - Công Ty TNHH Thương Mại Thiên Hương Phát', 'Đồng Phục Thái Bình - Công ty TNHH May MTV Minh Quân', 'Đồng Phục JUNI - Công Ty TNHH Quà Tặng Đồng Phục JUNI', 'Thời Trang Felegant Uniform - Công Ty TNHH Thời Trang Felegant Uniform', 'Đồng Phục Lami - Công Ty TNHH Sản Xuất May Đồng Phục Lami', 'Đồng Phục Bảo Trâm - Công Ty TNHH MTV Sản Xuất Thương Mại Bảo Trâm', 'Chi nhánh Đồng Nai - Công Ty TNHH Quốc Tế UNI-PRO Việt Nam', 'Công Ty TNHH Thương Mại Dịch Vụ Gia Sơn Phát', 'Đồng Phục Phước Thịnh - Công ty TNHH May In Phước Thịnh', 'Chi nhánh Bình Dương - Công Ty TNHH Quốc Tế UNI-PRO Việt Nam', 'Đồng Phục Khang Thịnh - Công Ty TNHH Sản Xuất Thương Mại Quốc Tế Khang Thịnh', 'Đồng Phục NDƯ - Công Ty TNHH SX – TM & DVDL NDƯ', 'May Mặc Việt Nữ - Công Ty TNHH May Mặc Việt Nữ', 'May Mặc Tân Phương - Công Ty TNHH May Mặc Tân Phương', 'May Mặc Hà Anh Dũng - Công Ty TNHH MTV May Thêu Hà Anh Dũng', 'Đồng Phục Vĩnh An - Công Ty TNHH Dịch Vụ Và Thương Mại Vĩnh An', 'May Mặc Tiến Đạt - Công Ty TNHH ĐT SX TM DV May Mặc Tiến Đạt', 'May Mặc An Việt - Công Ty TNHH Sản Xuất Thương Mại Thiết Kế An Việt', 'Đồng Phục Gia Mỹ - Công Ty TNHH Sản Xuất Thương Mại Dịch Vụ Xuất Nhập Khẩu Gia Mỹ', 'Công Ty TNHH Sản Xuất Thương Mại Happy Gift', 'Đồng Phục Chiến Thắng - Công Ty TNHH May CTS', 'Đồng Phục Bảo Duyên - Doanh Nghiệp Tư Nhân Bảo Duyên', 'Công Ty TNHH SX TM Bảo Hộ Lao Động Thanh Ngọc', 'Thời Trang De Charme - Công Ty Cổ Phần Thời Trang De Charme', 'Công Ty TNHH Nhật Minh Hương', 'Đồng Phục Bảo Thịnh Phát - Công ty TNHH Sản Xuất Thương Mại Dịch Vụ Bảo Thịnh Phát', 'Đồng Phục Hà Thành - Công Ty TNHH Đồng Phục Hà Thành', 'Đồng Phục Tín Quang - Công Ty TNHH May Mặc Xuất Nhập Khẩu Tín Quang', 'Đồng Phục Dũng Hoàng - Công Ty CP Sản Xuất Và Thương Mại Dũng Hoàng', 'Bảo Hộ Lao Động Dương Châu - Công Ty TNHH Bảo Hộ Lao Động Dương Châu', 'Chi Nhánh Cần Thơ - Công Ty TNHH Quốc Tế UNI-PRO Việt Nam', 'Công Ty TNHH Bảo Minh HBC' ]
Wow, ghê chưa? Lúc này bạn đã có dữ liệu là tên công ty của những trang vàng. Bạn muốn lấy dự liệu nào thì cứ như bước đầu tiên tôi chỉ nhé. CÒn bây giờ tương tự, thì chúng ta sẽ cào dữ liệu với 3 các còn lại.
JSDOM - web scraping
Tương tự như vậy ta sử dụng một thư viện khác như cheerio đó là jsdom
const { JSDOM } = require("jsdom")
const axios = require('axios')
const upvoteFirstPost = async () => {
try {
const { data } = await axios.get("https://www.yellowpages.vnn.vn/cls/268180/may-dong-phuc.html");
const dom = new JSDOM(data);
console.log(dom.window.document.querySelectorAll('div > h2.company_name > a').forEach(link => {
console.log(link.textContent);
}));
} catch (error) {
throw error;
}
};
upvoteFirstPost().then(msg => console.log(msg));Nightmare - web scraping
const Nightmare = require('nightmare')
const nightmare = Nightmare()
nightmare
.goto('https://www.google.com/')
.type("input[title='Search']", 'ScrapingBee')
.click("input[value='Google Search']")
.wait('#rso > div:nth-child(1) > div > div > div.r > a')
.evaluate(
() =>
document.querySelector(
'#rso > div:nth-child(1) > div > div > div.r > a'
).href
)
.end()
.then((link) => {
console.log('Scraping Bee Web Link': link)
})
.catch((error) => {
console.error('Search failed:', error)
})puppeteer - web scraping
Ở tips javascript có một bài viết nói về puppeteer là gì? Và cách sử dụng puppeteer.
const puppeteer = require('puppeteer')
async function getVisual() {
try {
const URL = 'https://www.reddit.com/r/programming/'
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto(URL)
await page.screenshot({ path: 'screenshot.png' })
await page.pdf({ path: 'page.pdf' })
await browser.close()
} catch (error) {
console.error(error)
}
}
getVisual()