Nội dung bài viết
Video học lập trình mỗi ngày
Tóm tắt phần trước
Ở phần trước chúng ta đã đến cập đến tuyền phòng thủ đầu tiên trong hệ thống DDD bán vé tàu TẾT - Đồng thời cao, ở đó có một khái niệm cân được quan tâm đó là circuitBreaker và RateLimiter. Cốt lõi là circuitBreaker nó sẽ phát huy tác dụng trong trường hợp đó chính là quấy bán vé quá tải thì phải lập tức chuyển qua trạng thái OPEN.
Lời đề nghị: Nên xem đừng bỏ qua DDD bán vé tàu TẾT - Xây dựng tuyến phỏng thủ đầu tiên
Link: Nếu bạn là một senior backend thật sự thì triển khai distributed cache có vấn đề như sau
Lập trình viên backend java kinh nghiệm xây dựng tuyến phòng thủ thứ hai
Ngoài ra thì chúng ta cũng đề cập đến 3 cách xây dựng tuyến phòng thủ của 3 anh chàng kỹ sư Backend như thế nào thông qua cách code và cách tesr show ra kết quả của hai level.
Ngay bây giờ chúng ta sẽ đi đến cách của anh chàng lập trình viên thứ 3 sẽ triển khai như thế nào? Đầu tiên khi tham gia một dự án có tính đồng thời cao như bán vé tàu tết thì tôi muốn anh chị hiểu về các công cụ chúng ta sử dụng và có 3 câu hỏi luôn được đưa ra mỗi khi sử dụng công cụ đó là?
- Công cụ đó để làm gì?
- Công cụ đó nhược điểm không?
- Vì sao lại sử dụng công cụ này mà không phải công cụ khác?
Chúng ta sẽ làm sáng tỏ vấn vấn đề này thông qua cách triển khai ở level thứ 3 này. Nếu các bạn không bỏ sót một bài nào thì có thể thấy rằng anh chàng lập trình viên thứ hai khi code sử dụng redis để bảo vệ mysql đã có vấn đề đúng không? Hãy quay lại review code anh ấy một chút
// Lập trình viên thứ hai có kinh nghiệm nhưng chưa triển khai dự án có tính đồng thời cao
public String getTicketItemCacheNormal(Long id, Long version) {
// 1. get ticket item by redis
String ticketItem = cacheService.getString(genTicketItemKey(id));
// 2. YES -> Hit cache
if (ticketItem != null) {
log.info("FROM CACHE {}, {}, {}", id, version, ticketItem);
return ticketItem;
}
// 3. If NO --> Missing cache
// 4. Get data from DBS
ticketItem = ticketRepository.findById(id);
log.info("FROM DBS {}, {}, {}", id, version, ticketItem);
// 5. check ticketitem
if (ticketItem != null) { // Nói sau khi code xong: Code nay co van de -> Gia su ticketItem lay ra tu dbs null thi sao, query mãi
// 6. set cache
cacheService.setString(genTicketItemKey(id), ticketItem);
}
return ticketItem;
}
Nhìn vào có vẻ rất logically, nhưng khi bên tester sử dụng jmeter thì đã có vấn đề, kết quả SAI ở bài trước chúng ta không nói thêm ở đây, mất thời gian.
Hãy phân tích đoạn code trước đó. Đầu tiên hãy để ý
String ticketItem = cacheService.getString(genTicketItemKey(id));
Bước này anh ấy sẽ truy cập cache, nếu như nó có dữ liệu chi tiết của một ticket thì chuyện này sẽ không đáng nói ở đây.. NHưng nếu ticketItem = null thì anh ấy sẽ cho phép luồng đi vào query mysql ở dòng lệnh tiếp theo
// 4. Get data from DBS
ticketItem = ticketRepository.findById(id);
log.info("FROM DBS {}, {}, {}", id, version, ticketItem);
Khoan hãy để ý, giả sử ticketItem = ticketRepository.findById(id); nó sẽ mất 1 giây để truy vấn trong Mysql thì hậu quả là gì? Nghĩa là ví dụ 1000 req cùng một thời gian sẽ vượt qua cache thì cache mất một giây đễ thiết lập dữ liệu cache. Như vậy 1 giây đó sẽ khiến Mysql bị áp lực rất nhiều có đúng không? Và kết quả ai cũng thấy rõ thông qua kết quả này.
Trông nó thật tệ phải không? OK, khi chúng ta nhận ra được lỗi thì đó là điều tuyệt vời. Cố gắng sửa đổi nó, không sao. Bây giờ cách khắc phục là thêm một công cụ.
Mutex - Distributed Cache
Bây giờ đơn giản nhìn nhận là chúng ta có 1000 req cùng một thời gian. Giả sử tôi sử dụng một công cụ X để giải quyết vấn đề này. Khi 1000 req xông vào lấy data thì chúng ta sẽ thiết lập như sau.
Đầu tiên là cho phép lấy cache như cách của lập trình viên thứ 2, và lúc này cache = null, sau đó tôi sẽ dùng X đóng cửa lại (lock), chỉ có phép một req đi vào trong để lấy dữ liệu từ mysql, sau đó sẽ mở cửa (unlock). Như vậy khi unlock thành công thì thằng thứ hai tương tự nó sẽ lock lại và đến lấy dữ liệu lúc này hãy đặt một lớp getCache ticketItem = cacheService.getString(genTicketItemKey(id)); trước khi truy cập mysql. Như vậy thì hiệu quả rất tốt, chúng ta sẽ chống chọi với bạo lực của người dùng. Nếu bạn chưa rõ thì có thể xem hình ảnh này. Nó rất rõ ràng
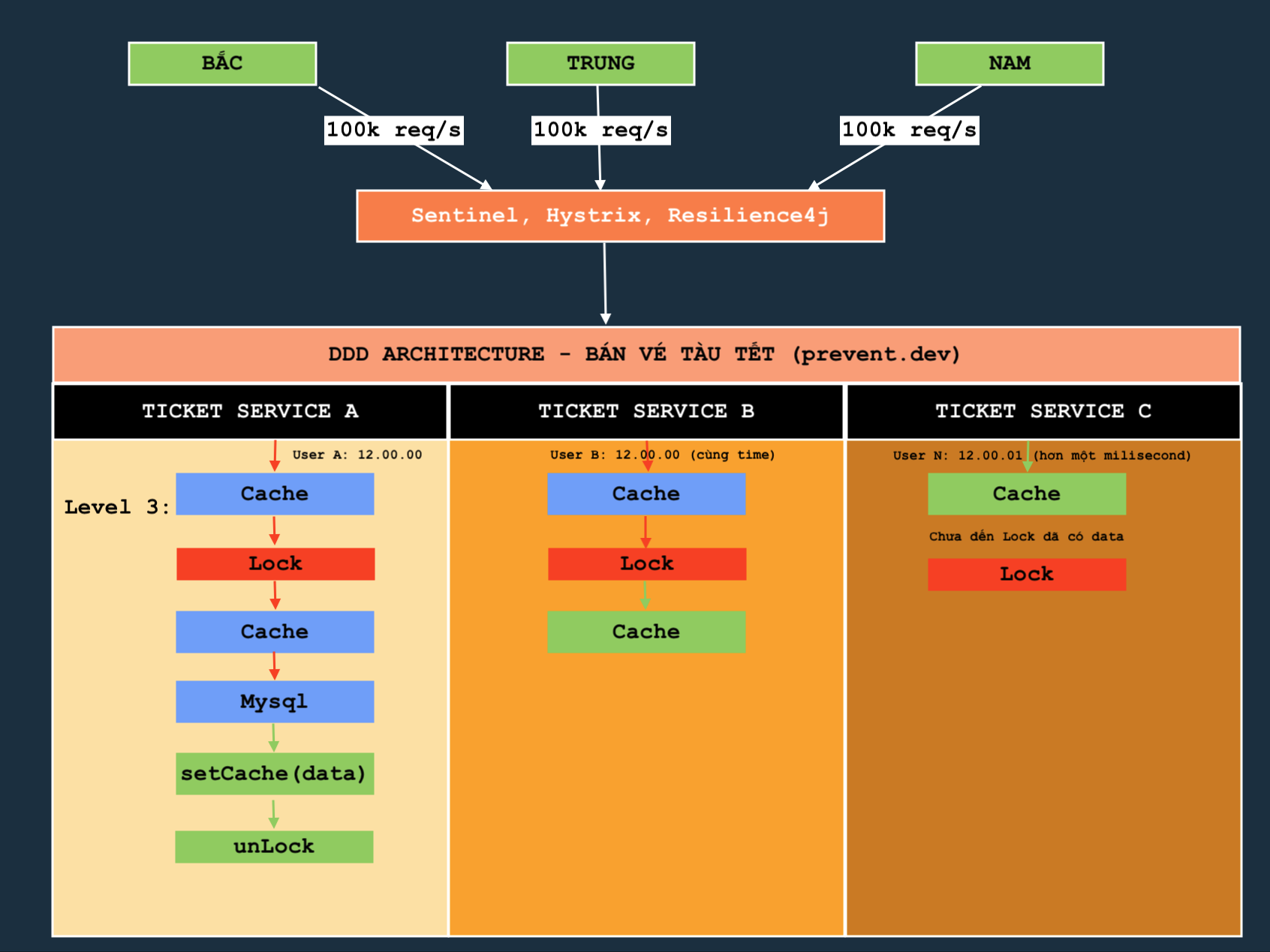
Chú ý là mũi tên xanh là có dữ liệu, màu đỏ thì không? Hiện tại thì mô hình phòng thủ thứ hai đã rõ hơn bao giờ hết. Chú ý ở đây là dự án có tính đồng thời cao cho nên việc có nhiều server hay service hoạt động là điều đương nhiên. Lúc này khái niệm Distributed Cache ra đời ( tối sẽ giải thích sau).
Đến đây ai cũng thở phào nhẹ nhõm, vậy công cụ lock ở đây sử dụng thằng nào? Chúng ta đi tìm hiểu một chút. Nếu như bên go có mutex, thì trong Java, mutex có thể được biểu diễn qua các lớp và giao diện đồng bộ hóa trong gói java.util.concurrent.locks và synchronized keyword, cụ thể như sau:
synchronized keyword: Đây là cách đơn giản nhất trong Java để tạo mutex. Khi một phương thức hoặc một khối mã được đánh dấu synchronized, chỉ có một luồng có thể truy cập vào phần mã đó tại một thời điểm.
Ví dụ:
public synchronized void updateCache() {
// Chỉ một luồng có thể truy cập vào phương thức này cùng một lúc
}
ReentrantLock trong java.util.concurrent.locks: Đây là một lớp cung cấp các tính năng giống như mutex nhưng linh hoạt hơn so với synchronized. ReentrantLock cho phép:
Kiểm soát tốt hơn việc lock và unlock. Hỗ trợ tính năng "fairness" để các luồng có thể cạnh tranh công bằng hơn. Cung cấp phương thức tryLock() để thử lock mà không bị block nếu không thành công. Ví dụ:
import java.util.concurrent.locks.ReentrantLock;
public class Cache {
private final ReentrantLock lock = new ReentrantLock();
public void updateCache() {
lock.lock();
try {
// Code cần được bảo vệ bởi mutex
} finally {
lock.unlock();
}
}
}
Cả synchronized và ReentrantLock đều được dùng để đảm bảo tính loại trừ lẫn nhau (mutual exclusion) trong Java, tương tự như cách dùng mutex trong Go.
Nhưng ở đây tôi chỉ show ra đơn giản ở cấp độ ngôn ngữ, còn ở hình ảnh trên thì nó gọi là mode phân tán, vì vậy phải sử dụng công cụ khác đó là redisson. Chúng ta bắt đầu showcode.
Trước khi showcode hãy chú ý, public thì code đơn giản, nhưng trong dự án DDD của member thì phải code kiểu khác vì nó mang tính thực tế hơn.
Lời đề nghị: Xem cách code chuẩn của Distributed Cache trong mô hình DDD
Bắt đầu review code...
// CHƯA VIP LẮM - KHI HỌ REVIEW CODE - SẼ BẮT VIẾT LẠI
public TicketDetail getTicketDefaultCacheVip(Long id, Long version) {
log.info("Implement getEventItemCacheVip->, {}, {} ", id, version);
TicketDetail ticketDetail = redisInfrasService.getObject(genEventItemKey(id), TicketDetail.class);
// 2. YES
if (ticketDetail != null) {
return ticketDetail;
}
// Tao lock process voi KEY
RedisDistributedLocker locker = redisDistributedService.getDistributedLock("PRO_LOCK_KEY_ITEM"+id);
try {
// 1 - Tao lock
boolean isLock = locker.tryLock(1, 5, TimeUnit.SECONDS);
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
if (!isLock) {
return ticketDetail;
}
// Get cache
ticketDetail = redisInfrasService.getObject(genEventItemKey(id), TicketDetail.class);
// 2. YES
if (ticketDetail != null) {
return ticketDetail;
}
// 3 -> van khong co thi truy van DB
ticketDetail = ticketDetailDomainService.getTicketDetailById(id);
log.info("FROM DBS ->>>> {}, {}", ticketDetail, version);
if (ticketDetail == null) { // Neu trong dbs van khong co thi return ve not exists;
// set
redisInfrasService.setObject(genEventItemKey(id), ticketDetail);
return ticketDetail;
}
// neu co thi set redis
redisInfrasService.setObject(genEventItemKey(id), ticketDetail);
return ticketDetail;
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
locker.unlock();
}
}
Code có vẻ rất rõ không có gì phải phàn nàn, nhưng hãy để ý cụm từ tôi nhận mạnh đến 6 lần:
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
Chỗ này rất quan trọng vì nếu như bạn không trao lại chìa khoá sau khi sử dụng xong, thì không ai có thể sử dụng dịch vụ được nữa... Có đúng không? hãy nhớ unLock().
Khoan đã đừng vội vỗ tay, có hai điều sai ở đây. Hãy phân tích nó vì chúng ta là những lập trình viên cao cấp đang triển khai dự án DDD - bán vé tàu tết có tính đồng thời cao và phức tạp.
Thiết kế này còn có rủi ro không?
Có... Thứ nhất nếu như anh chị mà đã sử dụng or có kinh nghiệm làm việc với cache thì đây có lẽ sẽ đặt ra một câu hỏi. Đó là Vì sao sử dụng Redisson trong khi hệ thống chp phép sử dụng LUA rất tốt. LUA là gì? Tôi không giải thích vì ở đây dành cho các lập trình viên có nhiều kinh nghiệm, nếu như bạn là ngưới mời vô tình đọc vào đầy thì tự tìm hiểu or tối sẽ demo cho anh chị.
Vì sao lại không sử dụng LUA trong tình huống lock distributed cache này? Lý do tôi chuẩn bị nói, và có trong các câu hỏi phỏng vấn backend lương 2k5 trở lên. Chúng ta đang chuân bị nói đến Thuật toán Redlock và triển khai Redisson trong môi trường phân tán. Đề nghị các lập trình cao cấp ở lại một chút
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.37.0</version>
</dependency>
Redisson đã gói gọn thuật toán redlock như thế nào và vì sao chúng ta lại sử dụng nó thay vì sử dụng LUA. ở đây chưa nói đến Cluster, nếu nói đến thì sự lựa chọn Redisson thật là tuyệt với và đúng đắn.
Hãy nhìn lại code một lần nữa...
boolean isLock = locker.tryLock(1, 5, TimeUnit.SECONDS);
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
// Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá.
if (!isLock) {
return ticketDetail;
}
// Get cache
ticketDetail = redisInfrasService.getObject(genEventItemKey(id), TicketDetail.class);
Giả sử luồng này mới tới đây thì distributed cache bị crash bởi một luồng nào đó ở service khác. Vì nó là cache phân tán. Vì vậy tình huống này nếu như, nếu như bạn sử dụng LUA thì có thể không bao giờ unLock() và dẫn tới câu của tôi Lưu ý: Cho dù thành công hay không cũng phải unLock, bằng mọi giá. khi sử dụng script LUA để thực hiện thao tác lock và unlock trong Redis, có một rủi ro là nếu Redis server gặp sự cố hoặc bị crash, lock có thể không được tự động giải phóng or nếu có thì việc triển khai rất phức tạp với mô hình cluster. Đây là do script LUA chỉ chạy trên một node Redis đơn lẻ, nên nếu node đó không còn hoạt động, các lock chưa được unlock sẽ vẫn còn giữ nguyên trạng thái.
Ồ có một bạn lên tiếng rằng nếu redis chết thì không thể get data được nữa và đòi vào lock với unlock.. Khà khà, bình tĩnh, hãy suy nghĩ đến việc lớn hơn là cluter, một thằng chết thì đâu có dừng lại, nó vẫn tiếp tục nha bạn yêu.
Chết thật, lúc này khoá đã bị mất, không một ai có thể lấy nó, treo cho đến khi init lại cache. Thật tồi tệ khi sử dụng LUA trong tình huống này đúng không? Vậy LUA có tốt hay không và nó được sử dụng ở đâu? Thì nó rất tốt và tôi sẽ sử dụng nó ở khấu trừ hàng tồn kho khi mở bán vé, ở đây chúng ta chưa đề cập dến nó. Dừng lại
Nhưng với Redisson thì khác, chúng ta không đi sâu vào code Redisson, chúng ta chỉ nói qua kinh nghiệm mà tôi bị một lần, do đó hãy sử dụng Redisson, với Redisson, vấn đề này có thể được giảm thiểu vì Redisson có cơ chế quản lý lock phức tạp hơn và hỗ trợ các tính năng như tự động giải phóng (auto-expiration) và lock với thời gian chờ (TTL). Redisson cũng có khả năng tái tạo lock nếu Redis cluster có nhiều node và một trong các node bị lỗi.
Có thể hiểu ngắn gọn và xúc tích rằng: "Redisson yêu cầu người dùng chỉ định khóa cho khóa, nhưng không cần chỉ định thời gian hết hạn cho khóa vì nó có thời gian hết hạn mặc định (tất nhiên cũng có thể chỉ định). Vì khóa có chức năng "reentrant", Redisson sẽ tạo một bộ đếm cho khóa để ghi lại số lần một luồng vào lại khóa."
OK giờ chúng ta đã rõ, nếu muốn chi tiết hơn hãy cố gằng tìm hiểu code trong Redisson họ đã làm những gì mà tốt đến vậy.
OK, vậy vấn đề thứ hai là gì? Đó chính là câu này:
// CHƯA VIP LẮM - KHI HỌ REVIEW CODE - SẼ BẮT VIẾT LẠI
Anh chị lập trình cấp cao nhìn vào có thể thấy ngay đây là bad code, rất khó phát triển, vì nó vi phạm đạo đức à vi phạm S trong SOLID, Giải thích cạn cẽ về Single-responsibility Principle nghĩa là nó làm nhiệu trách nhiệm trong một function. Cụ thể ở đây là, lấy cache, set lock, get dbs, set cachce... rất nhiều, vậy nếu như bạn thì bạn sẽ refactor nó như thế nào?
Xem thêm về: DESIGN PATTERN vs SOLID: Sự khác nhau là gì? Nên học gì trước? Tôi là anti của S trong SOLID. Nếu chưa nghĩ ra thì video sau chúng ta sẽ refactor nó. OK xin chào! Hẹn video tiếp theo hen
