Nội dung bài viết
Video học lập trình mỗi ngày
Sau khi chúng tôi được gặp Giám Đốc A thì công ty đã có nhiều chuyển biến về mặt kinh doanh, nhờ vào những tính năng kích hoạt thương mai điện tử ở bài trước, và cộng vào SEO của công ty cho nên công ty chúng tôi đã có một thành tích nhất định.
Bài viết trước: Hệ thống chậm, tôi chuẩn bị thất nghiệm thế nào?
Về mặt tiền bạc thì chúng tôi không biết thu về bao nhiêu, nhưng chúng tôi là những lập trình viên nên chỉ hiểu là công ty hiện tại đã có 100.000 dùng đăng ký sử dụng hệ thống, sau đó chúng tôi thống kê thì có tới 5000 người hoạt động mỗi ngày. Oà một con số ấn tượng đối với một công ty khởi nghiệp nhỏ. Tiếp theo chúng tôi xem xét về Database thì có tới 1K data được lưu mỗi ngày và thống kê mỗi giây tối đa server chịu được tải là 10 request mỗi lần. Với một server 32G và 16 lõi thì vô tư.
Đến đây thì dừng lại một chút, bởi vì hệ thống chúng tôi đáng sử dụng 2 loại Database đó là Mysql và Mongodb. Phần Mongodb là chúng tôi quyết định tạo ra phục vụ cho việc lưu trữ logs của hệ thống cũng như hệ thống sendMail. Với kỹ thuật sendMail lớn thì chúng tôi không ngần ngại sử dụng thêm phần hỗ trợ đó là RabbitMQ. Và khi chúng tôi thực hiện connect Mysql với số lượng lớn thì một lỗi đã xảy ra, đó là hệ thống rất chậm chạp. Chính vì vậy chúng tôi quyết định thử hiệu suất kết nối giữa Connection Pooling trong MySQL và Nodejs.
Như bài trước tôi cũng đã đề cập là một hệ thống setup khởi nghiệp không phải là hoàn hảo, Bởi vì một hệ thống mới khởi nghiệp thì chủ yếu là để phát triển nhanh các chức năng kinh doanh trong thời gian đầu và phát triển một hệ thống đơn khối để triển khai trên một hệ thống. Ở đây bạn sẽ phải tìm hiểu hệ thống đơn khối là gì? Hay còn gọi là hệ thống độc lập? Như hình trên.
Cách thiết kế Database đáp ứng truy xuất cao
Cho đến một ngày, chúng tôi được bơm tiền làm quảng cáo và có nhiều tai to mặt lớn sát nhập thì đã đưa chúng tôi đến con đường mà nhiều người mơ ước. Công việc kinh doanh của công ty phát triển nhanh chóng, chỉ sau vài tháng, số người đăng ký đã lên tới 10 triệu! 0,5 triệu người dùng hoạt động hàng ngày! Lượng dữ liệu mới được thêm vào trong một bảng duy nhất đạt 250.000 mỗi ngày! Số lượng yêu cầu mỗi giây trong thời kỳ cao điểm lên tới 10.000! Con số thật là ấn tượng. Shopee có thể đã vượt qua con số đó tại thời điểm tôi đang viết bài này.
Việc số lượng yêu cầu mỗi giây là 10.000 (request/second) thì chúng tôi đã thực hiện triển khai 20 servers để đối phó, với việc sử dụng công nghệ Load Balancing thì chúng tôi chia đều thì mỗi máy chủ hiện tại chịu 500 request/second. Rất tiện lợi và thực hiện điều này có thể được chống lại tính đồng thời cao và không có vấn đề gì lớn với 20 máy chủ hoạt động ổn định. Nhưng những gì về cấp độ cơ sở dữ liệu thì nó có vấn đề...
Các bạn nhớ chú ý đến các con số mà tôi đã tô màu vàng nhé. Đó là những số liệu chúng ta phải giải bài toán nếu bạn là một lập trình viên chính hiệu. Bây giờ một tin vui là chúng ta đã là một công ty khởi nghiệp có tiếng, và tin buồn là hệ thống của chúng ta đang diễn ra quá chậm so với kỳ vọng của công ty, giờ đây chúng ta làm thế nào đây??
Phân tích tình huống thiết kế dữ liệu
Được rồi, hiện tại ai cũng đang rất là áp lực và cảm thấy nặng nề. Tới công ty lúc 7h và ra về lúc 22h đêm. Khi đi con chưa dậy, khi về con đã ngủ... Tại sao nó lại gây nặng nề cho chúng tôi. Tại sao vậy?
Chúng tôi ngồi lại và phân tích, nếu như mỗi ngày có 250.000 đơn hàng vào dữ liệu thì một tháng chúng ta sẽ có bao nhiêu? 250.000 x 30 = 7.500.00, con số 7.5 triệu records trong một tháng, quá khủng. Và nếu như vậy thì 1 năm chúng tôi sẽ có bao nhiêu dữ liệu trong một bảng. Hãy nhớ, rằng là một BẢNG nhé. Vì sao một bảng thì trên kia tôi đã nói, và nhắc lại một lần nữa ở đây đó là vì chúng ta là một công ty khởi nghiệp và chưa hoàn hảo về hệ thống. Con số không dừng ở đó bởi vì tình hình kinh doanh càng tốt.
Tuy nhiên, chứng kiến hiệu suất của hệ thống truy cập cơ sở dữ liệu ngày càng kém đi, lượng dữ liệu trong một bảng càng ngày càng lớn, điều này đã kéo giảm hiệu suất của một số câu truy vấn phức tạp trong SQL hay nói cách khác là kiến trúc dữ liệu của chúng tôi sẽ phải thay đổi. Bởi vì không sớm thì muộn, một máy chủ cơ sở dữ liệu hỗ trợ hàng chục nghìn yêu cầu mỗi giây thì sẽ chết vào lúc cao điểm là chắc. Cao điểm ở đây là, nhận voucher, deal hot chủa shopee...
- Disk IO, băng thông mạng, CPU và mức tiêu thụ Memory của máy chủ cơ sở dữ liệu của bạn đều sẽ đạt đến điều kiện rất cao.
- Tổng tải của máy chủ nơi đặt cơ sở dữ liệu sẽ rất nặng, hoặc thậm chí gần như quá tải.
- Trong thời kỳ cao điểm, lượng dữ liệu trong một bảng của bạn rất lớn và hiệu suất SQL không tốt lắm.
Lúc này, cùng với sự suy giảm hiệu suất của máy chủ cơ sở dữ liệu do tải quá cao, bạn sẽ thấy rằng Hiệu suất SQL kém hơn. Cảm nhận rõ nhất là mọi chức năng trong hệ thống của bạn chạy rất chậm trong thời gian cao điểm, trải nghiệm người dùng rất kém, có thể mất hàng chục giây mới có kết quả khi bạn bấm vào một nút. Và điều tệ nhật là die.
Lúc đó thế giới quay lưng với chúng ta... Vì chúng ta chưa có kinh nghiệm thiết kế database lúc còn sơ khai.
Thiết kế hệ thống hàng triệu người dùng
Ai cũng mất bình tĩnh trước tình huống thế này, nhưng bạn hãy từ từ phân tích xem trước hết, chúng ta hãy xem xét câu hỏi đầu tiên: Làm thế nào để cơ sở dữ liệu hỗ trợ hàng chục nghìn yêu cầu đồng thời mỗi giây? Để làm rõ vấn đề này, trước tiên bạn phải hiểu cơ sở dữ liệu chung được triển khai trên máy chủ cấu hình nào. Nói chung, nếu bạn sử dụng một máy chủ có cấu hình chung để triển khai cơ sở dữ liệu, thì đó ít nhất là cấu hình máy 32G 16 lõi.
Bởi vì sao lại chọn nó, vì loại cơ sở dữ liệu này được triển khai bởi một cấu hình này là rất phổ biến, và có một kinh nghiệm chung mà chúng tôi học được từ các công nghệ khác đó là đừng bao giờ để nó hỗ trợ request 2000 mỗi giây. Phải kiểm soát dưới 2000 request/seconds với cấu hình này.
Chính vì vậy, bước đầu tiên là triển khai 5 máy chủ trong kịch bản hàng chục nghìn yêu cầu đồng thời và triển khai một cơ sở dữ liệu trên mỗi máy chủ. Sau đó, trong mỗi cá thể cơ sở dữ liệu, hãy tạo cùng một loại data, đó là đơn hàng như bài trước.
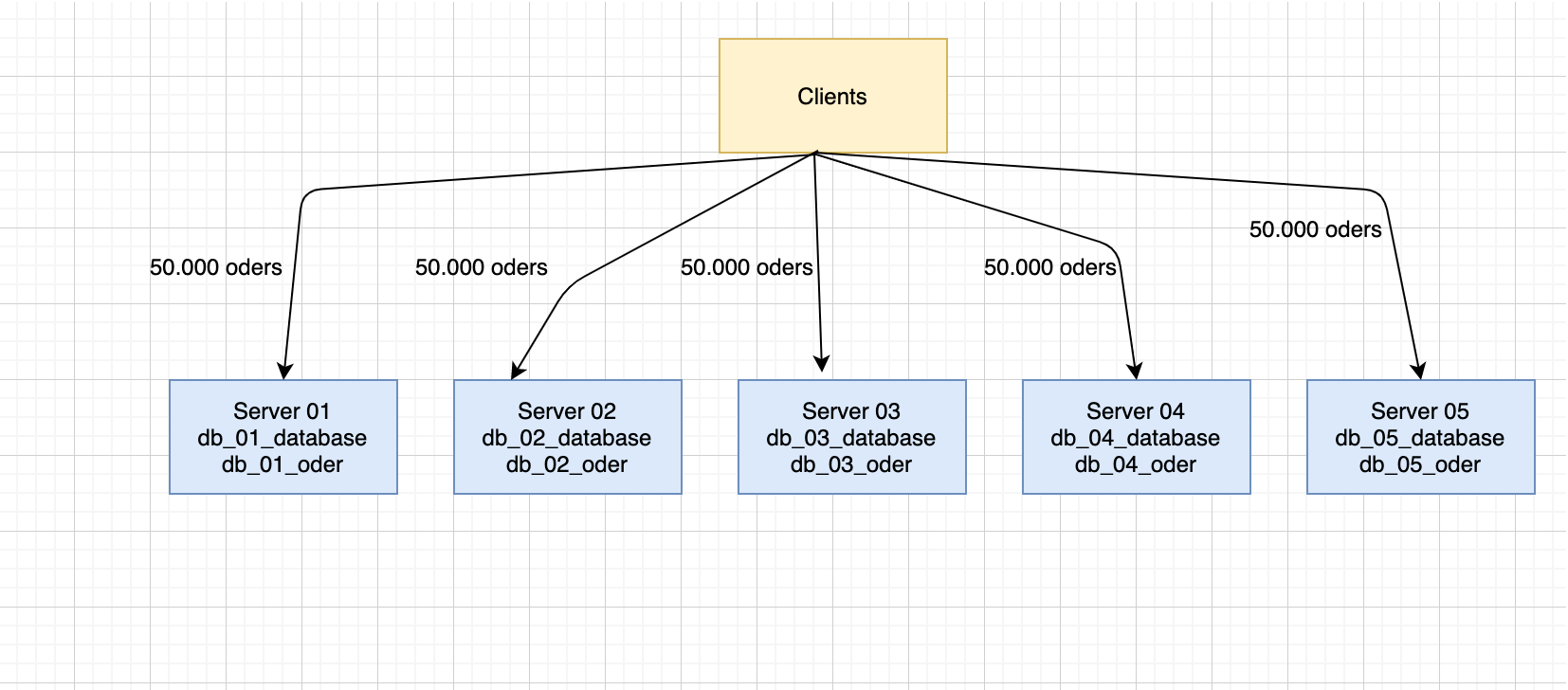
Tại thời điểm này, có 5 database trên 5 máy chủ, tên có thể tương tự như: db_01_database, db_02_database, ... , db_05_database Sau đó chúng ta triển khai mỗi server sẽ có một table chưa đơn hàng,
Ví dụ: db_01_database có db_01_oder, tương tự như vậy chúng ta sẽ có db_05_database có db_05_oder. Điều này là gì, đó là một kỹ thuật được biết nhiều đó là thực hóa ý tưởng cơ bản về cơ sở dữ liệu con và tách bảng trong mô hình thiết kế CSDL. Cụ thể ở đây đó là, tách 1 server CSDL ra thành 5 con server. Cơ sở dữ liệu gốc trở thành 5 cơ sở dữ liệu và mỗi bảng oder gốc trở thành 5 bảng oder con. Để làm gì, hãy xem mô hình để hiểu.
Nếu muốn ghi dữ liệu theo mô hình này bạn phải cần đến phần mềm trung gian của cơ sở dữ liệu như mycat, hay sharding-jdbc hay Shading mongodb ... or tự code cũng được, nhưng hiệu suất kết nối không cao???
Đọc lại ở trên bài viết thì nếu lúc trước khi tách servers thì 250.000 dữ liệu được thêm vào bảng đơn đặt hàng mỗi ngày, thì bây giờ sẽ có 50.000 phần dữ liệu sẽ rơi vào bảng db_01_oder của thư viện db_01_database, và 50.000 phần dữ liệu khác sẽ rơi vào thư viện db_02_database. Bảng db_02_oder, v.v. Bạn có thật sự hiểu là chúng tôi đã sử dụng thuật toán để chia đều dữ liệu ra 5 phần bằng nhau cho 5 con server chưa?? Nếu chưa, hãy tiếp tục theo dõi.
Lợi ích của việc thực hiện bước này là gì? Ưu điểm đầu tiên là ví dụ bảng đơn hàng chỉ có một bảng, lúc này thành 5 bảng thì dữ liệu của mỗi bảng trở thành 1/5. Và nếu tình hình kinh doanh ngon nghẻ thì nếu 500.000 dữ liệu được thêm vào mỗi ngày, thì mỗi bảng chỉ thêm 100.000 dữ liệu. Điều này ban đầu có làm giảm bớt vấn đề về khối lượng dữ liệu bảng đơn lẻ quá mức ảnh hưởng đến hiệu suất hệ thống không?
Ngoài ra, có 10.000 yêu cầu mỗi giây đến 5 cơ sở dữ liệu và mỗi cơ sở dữ liệu mang 2.000 yêu cầu mỗi giây. Yêu cầu đồng thời của mỗi máy chủ cơ sở dữ liệu có được giảm xuống phạm vi an toàn không? Bằng cách này, tải tối đa của cơ sở dữ liệu được giảm xuống và hiệu suất cao nhất cũng được đảm bảo.
Vậy là ngon. Tuy nhiên, sau một thời gian chúng tôi chợt nhận ra rằng, nếu như mô hình này để như vậy và đến một ngày dữ liệu trong một bảng quá lớn. Bây giờ bảng thứ tự là chia thành 5 bảng nên nếu mỗi năm có 100 triệu đơn hàng thì Mỗi bảng có 20 triệu lượt nhập vẫn là quá lớn. Vậy một bài toán được đặt ra ở đây như thế nào? Bài sau chúng ta sẽ đi vào hệ thống lớn của hệ thống thương mại shopee.
Ngoài ra bạn nên đọc lại bài viết trước để xem xét chúng tôi đã sử dụng Message Queue để làm hệ thống đặt hàng như thế nào?
Bài viết trước: Hệ thống chậm, tôi chuẩn bị thất nghiệm thế nào?
Tham khảo thêm:
https://www.programmersought.com/article/90744307217/ https://www.red-gate.com/simple-talk/sql/performance/designing-highly-scalable-database-architectures/
https://medium.com/@mikesparr/things-i-wish-i-knew-when-starting-software-programming-3508aef0b257
